About Me
I am a fourth-year Ph.D. student at the Institute for Interdisciplinary Information Sciences (IIIS), Tsinghua University, advised by Prof. Li Yi (弋力).
I also work as an AI Researcher at Memories.ai, working with Prof. Shawn Shen (University of Bristol).
My research interests lie in 4D Human-Object Interaction (HOI), Embodied AI, and Multimodal Large Language Models (MLLMs). I am passionate about equipping robots with the ability to understand and interact with the dynamic 4D world.
News
- Nov 2025 Two paper accepted to WACV 2026.
- Jun 2025 TupleInfoNCE paper surpassed 100+ citations.
- Nov 2025 My total citations surpassed 600+.
- Jun 2025 HOI4D dataset surpassed 200+ citations.
- Aug 2025 One paper accepted to ACM MM 2025.
- Jul 2025 One paper accepted to ICCV 2025.
- Jul 2025 One paper accepted to EMNLP 2025.
- May 2025 One paper accepted to UAI 2025.
- Feb 2025 Two paper accepted to CVPR 2025.
- Nov 2024 One paper accepted to 3DV 2025.
- Jul 2024 One paper accepted to ACM MM 2024 (Oral).
- Feb 2024 One paper accepted to CVPR 2024.
- Jan 2024 One paper accepted to ICRA 2024.
- Jul 2023 One paper accepted to ICCV 2023.
- Feb 2023 One paper accepted to CVPR 2023.
- Jul 2022 One paper accepted to ECCV 2022.
- Jul 2021 One paper accepted to ICCV 2021.
Publications
* denotes equal contribution, ^ denotes corresponding author.
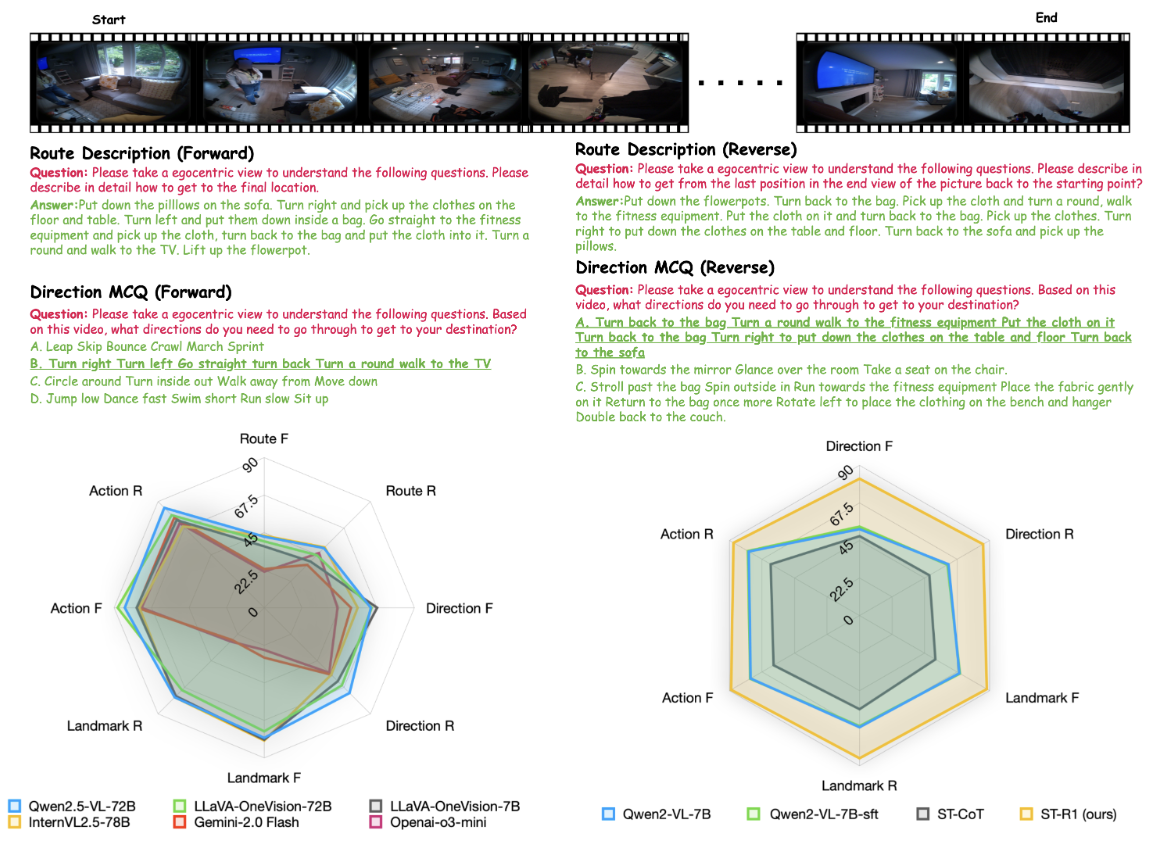
ST-Think: How Multimodal Large Language Models Reason About 4D Worlds from Ego-Centric Videos
WACV, 2026
Investigating how multimodal large language models understand and reason about dynamic 4D environments from ego-centric video inputs.

PointNet4D: A Lightweight 4D Point Cloud Video Backbone for Online and Offline Perception in Robotic Applications
WACV, 2026
Proposes PointNet4D, a lightweight hybrid Mamba-Transformer 4D backbone with 4DMAP pretraining for efficient online and offline point cloud video perception in robotics, achieving strong results across 9 tasks and enabling 4D Diffusion Policy and 4D Imitation Learning on RoboTwin and HandoverSim benchmarks.

CULTURE3D: A Large-Scale and Diverse Dataset of Cultural Landmarks and Terrains for Gaussian-Based Scene Rendering
ICCV, 2025
Introduces a 10-billion-point ultra-high-resolution drone dataset of 20 culturally significant landmarks and terrains, enabling large-scale Gaussian-based 3D scene reconstruction and benchmarking.

X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
EMNLP (Findings), 2025
Builds a life-logging simulation pipeline and benchmark with 432 ultra-long egocentric video logs (23 minutes–16.4 hours) to stress-test multimodal LLMs on temporal reasoning, memory, and context aggregation.
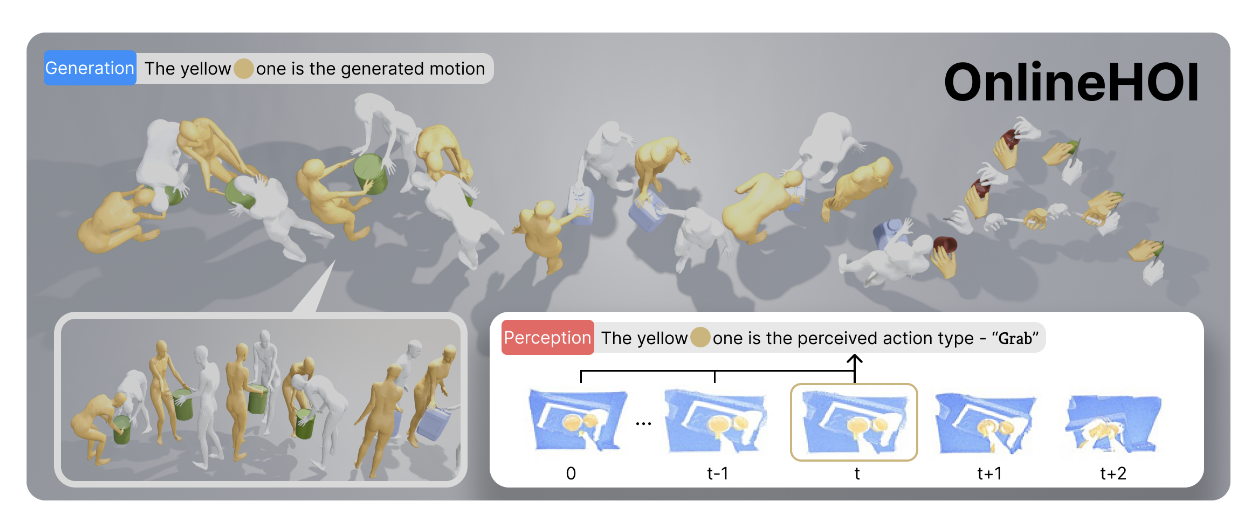
OnlineHOI: Towards Online Human-Object Interaction Generation and Perception
ACM Multimedia (ACM MM), 2025
Presents an online framework that jointly predicts future human motions and perceives object states for streaming HOI scenarios.
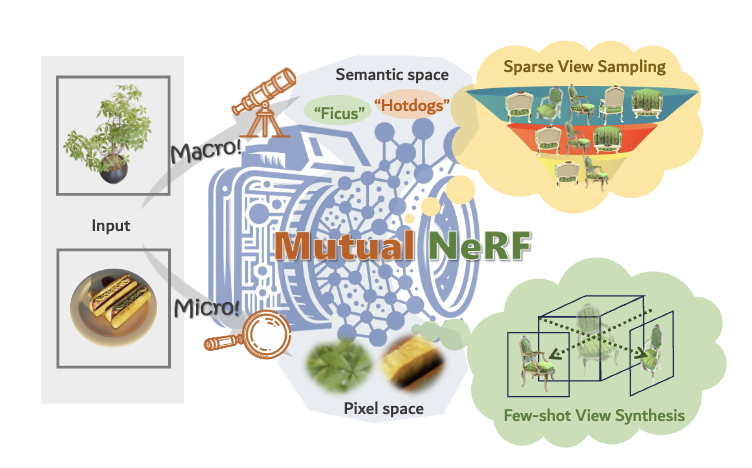
MutualNeRF: Improve the Performance of NeRF under Limited Samples with Mutual Information Theory
Uncertainty in Artificial Intelligence (UAI), 2025
Proposes MutualNeRF, a mutual-information-driven framework that improves NeRF under limited views via MI-guided sparse view sampling and few-shot regularization in both semantic and pixel spaces.

MAP: Unleashing Hybrid Mamba-Transformer Vision Backbone's Potential with Masked Autoregressive Pretraining
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Introduces Masked Autoregressive Pretraining that jointly optimizes Mamba and Transformer blocks via local MAE-style reconstruction and global autoregressive generation, yielding state-of-the-art hybrid vision backbones.
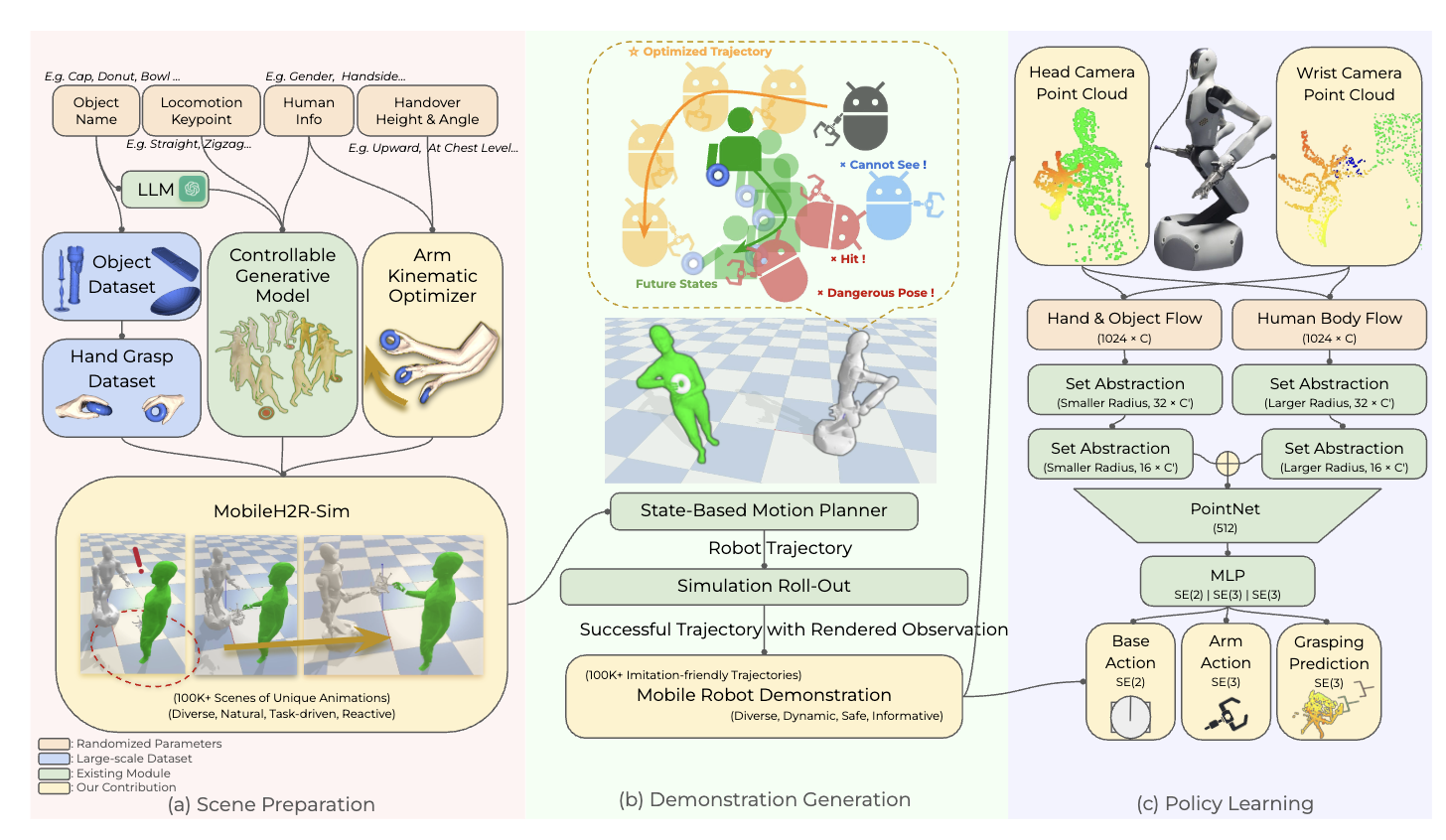
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Scales 100K+ synthetic handover scenes and distills them through 4D imitation learning into safe, generalizable mobile robot policies that outperform baselines by at least 15% success in sim and real.
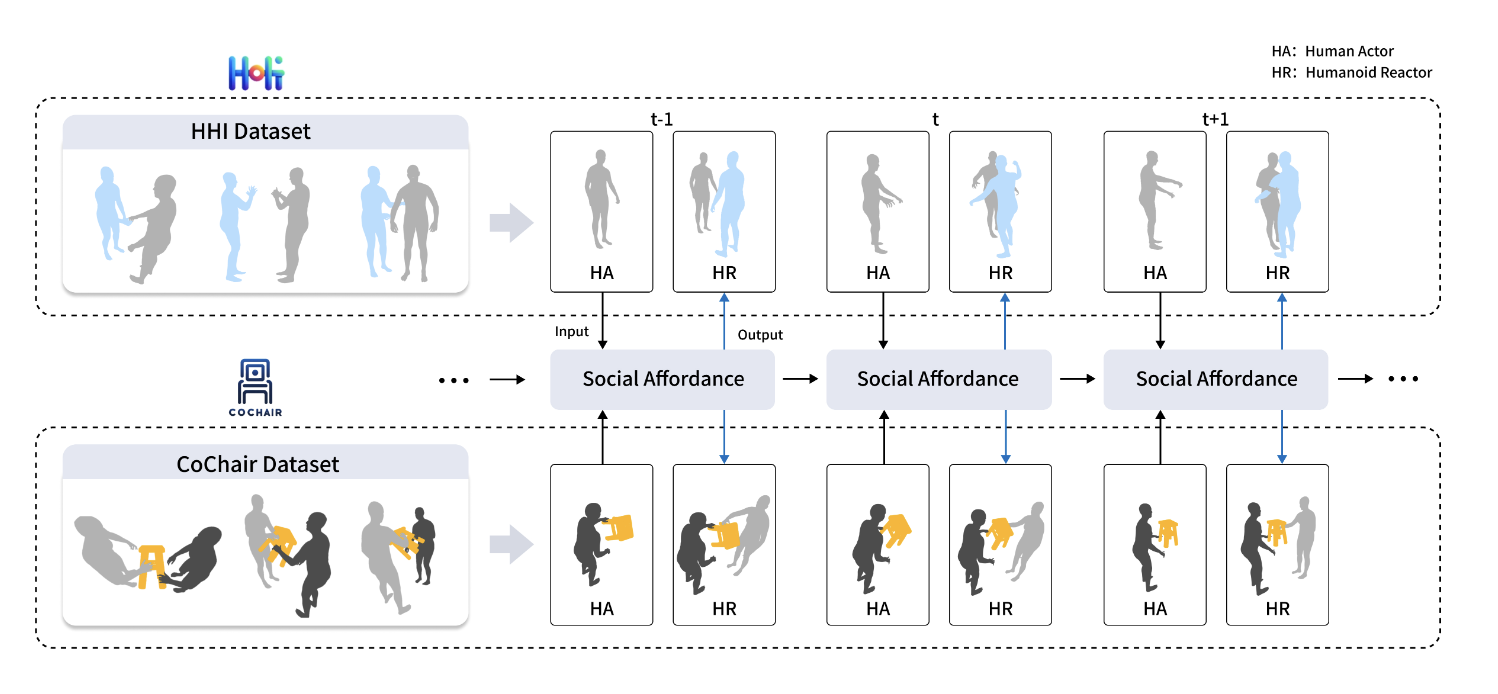
Interactive Humanoid: Online Full-Body Motion Reaction Synthesis with Social Affordance Canonicalization and Forecasting
International Conference on 3D Vision (3DV), 2025
Proposed a framework for synthesizing physically plausible humanoid reactions using forward dynamics guidance and social affordance forecasting.

PhysReaction: Physically Plausible Real-Time Humanoid Reaction Synthesis via Forward Dynamics Guided 4D Imitation
ACM Multimedia (ACM MM), 2024 (Oral Presentation)
Leveraging forward dynamics to guide 4D imitation learning for realistic humanoid reactions.

CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding
IEEE International Conference on Robotics and Automation (ICRA), 2024
Introduces CrossVideo, a self-supervised cross-modal contrastive learning framework for point cloud video understanding.
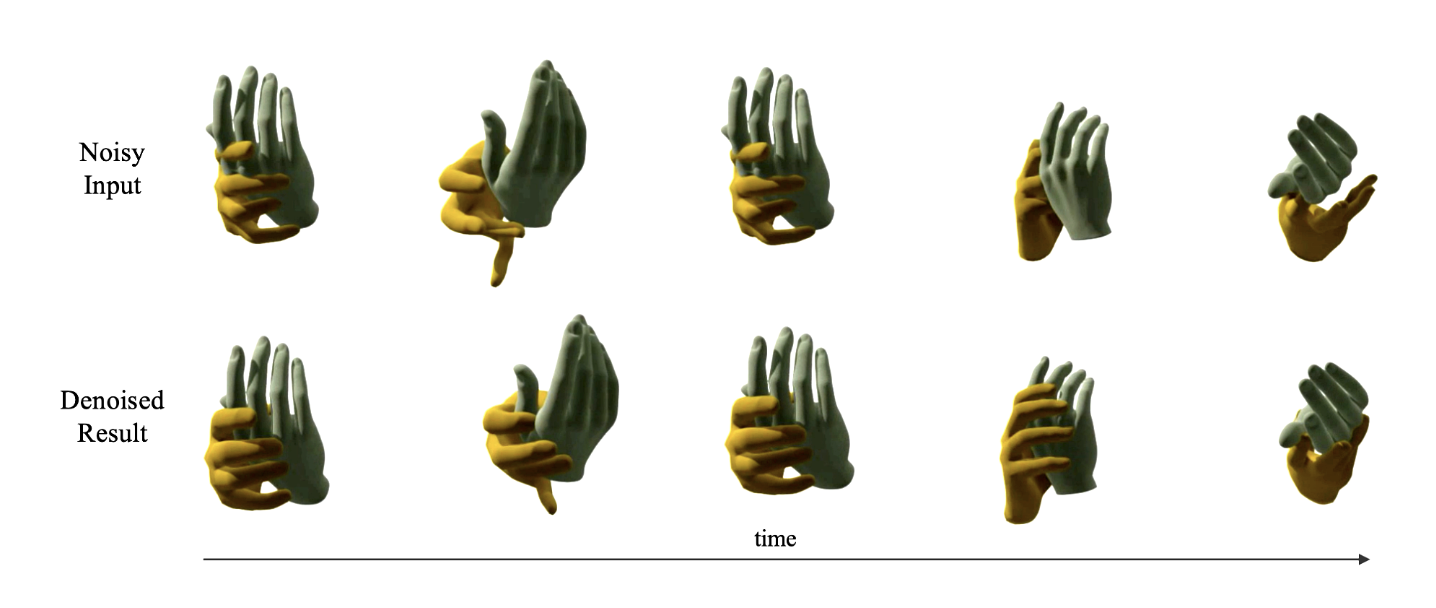
Physics-aware Hand-object Interaction Denoising
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Proposes a physics-aware hand-object interaction denoising framework that leverages physical constraints to improve the accuracy of hand-object interaction predictions.
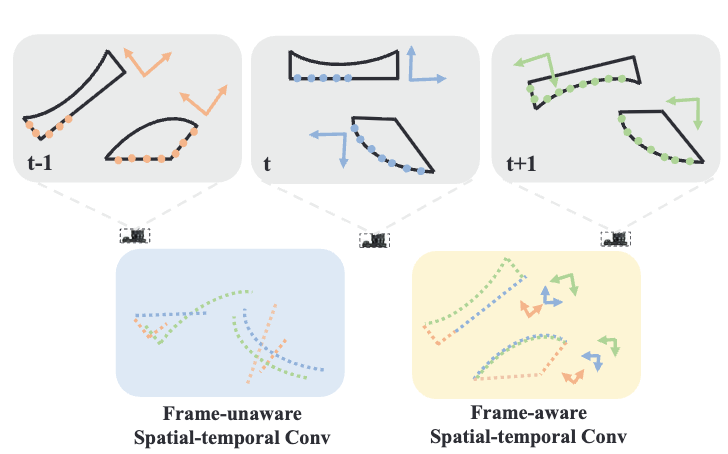
LeaF: Learning Frames for 4D Point Cloud Sequence Understanding
IEEE/CVF International Conference on Computer Vision (ICCV), 2023
Introduces learnable frame representations to effectively capture temporal dynamics in 4D point cloud sequences.

Complete-to-Partial 4D Distillation for Self-Supervised Point Cloud Sequence Representation Learning
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Introduces a complete-to-partial 4D distillation framework that leverages self-supervised learning to improve the performance of point cloud sequence representation learning.
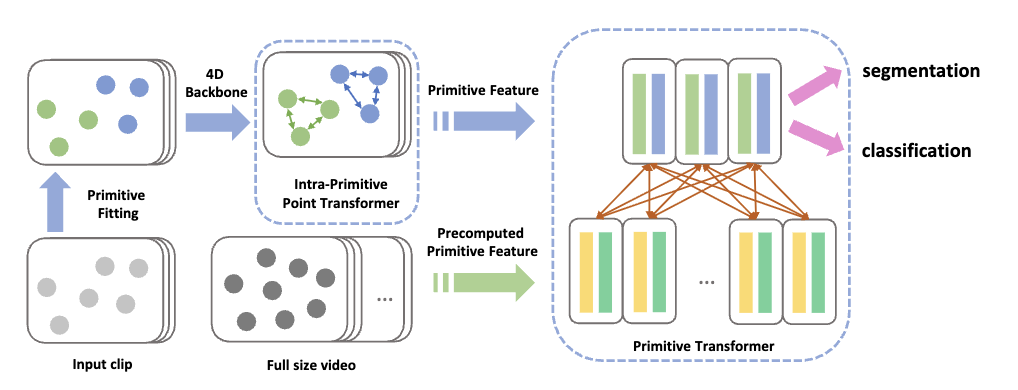
Point Primitive Transformer for Long-Term 4D Point Cloud Video Understanding
European Conference on Computer Vision (ECCV), 2022
Introduces a point primitive transformer for long-term 4D point cloud video understanding.
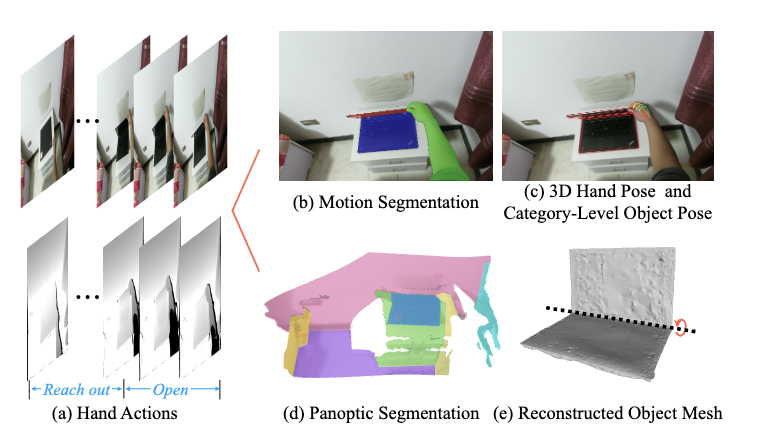
HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Releases HOI4D, a large-scale egocentric 4D HOI dataset with category-level annotations that enables learning robust human-object interaction perception and manipulation policies.
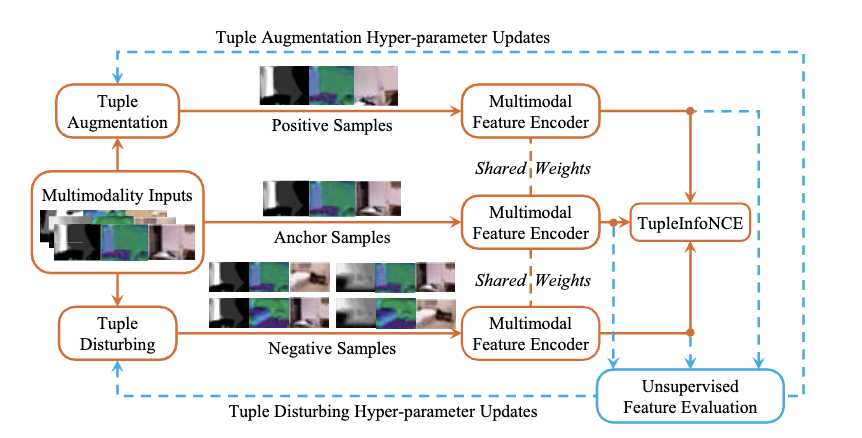
Contrastive Multimodal Fusion with TupleInfoNCE
IEEE/CVF International Conference on Computer Vision (ICCV), 2021
Introduces a contrastive multimodal fusion framework that leverages tuple-based contrastive learning to improve the performance of multimodal fusion.
Academic Services
- Conference Reviewer: CVPR, ICCV, ECCV, ACM MM, ICLR, NeurIPS, ICML, 3DV, WACV, AAAI
- Journal Reviewer: TMM
- Workshop Organizer: CVPR 2023 Workshop on 4D Hand Object Interaction